Soy bibliotecaria. A la gente le gusta más el término documentalista o incluso gestora de la información, pero me quedo con bibliotecaria. Eso sí, no soy la bibliotecaria que está sentada en un despacho esperando a que alguien venga a por un libro. Yo soy la que te ofrece ese libro antes de que sepas que lo necesitas. Soy la que te acerca la información que parecía imposible de conseguir. Soy la que te asesora cuando tienes dudas en tu investigación. Soy la que te ofrece herramientas para que puedas escribir y publicar tu artículo científico. Soy la que te ayuda a localizar información en Internet para que tus pacientes puedan entender lo que les pasa. Soy quien está pendiente de las actualizaciones para que tú no te preocupes más que por tu trabajo. Soy la que te ayuda en tu formación continuada. Soy la que siempre se está formando para que tú estés actualizado. Soy tu bibliotecaria médica de cabecera. Y para las organizaciones, soy Librarian as a service.
Actualmente, las inteligencias artificialesgenerativas, como los LLM, están en boca de todos, pero ¿sabemos cómo funcionan? ¿Qué significan para nuestro futuro y cómo nos afectan?
En Alter Biblio, nos esforzamos por mantenernos actualizados en los avances tecnológicos y de datos. Desde nuestro inicio, hemos estado comprometidos con la difusión de información y conocimiento, y no podemos ignorar esta revolución.
Hemos organizado una charla gratuita y divulgativa para aquellos interesados en comprender los fundamentos de los algoritmos de inteligencia artificial. De manera amigable, exploraremos cómo funcionan los algoritmos generativos, su impacto en la sociedad y las implicaciones en nuestra vida cotidiana. Analizaremos los beneficios y riesgos de estas tecnologías, y especularemos sobre el rumbo de estos avances en un futuro cercano.
Juan Antonio Casado, socio de Alter Biblio y experto en innovación y tecnología, ofrecerá una perspectiva iluminadora en medio del ‘hype’ actual.
La charla se transmitirá en vivo a través de Zoom el próximo martes 4 de abril a las 16:00h (Madrid). Aunque hay un límite de 100 plazas y es necesario registrarse: https://bit.ly/IA-generativas
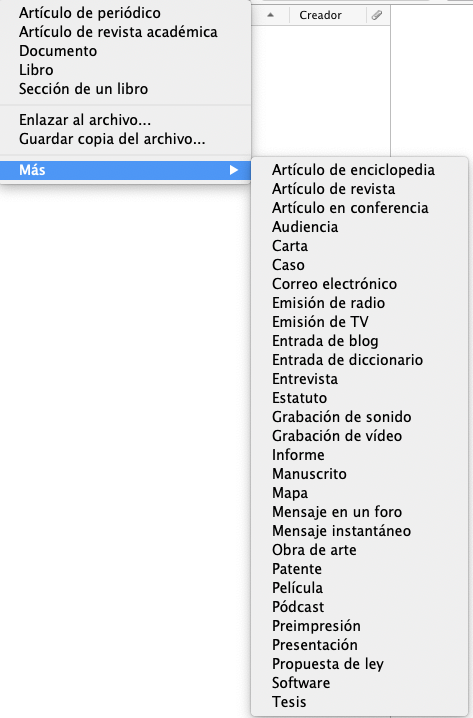
Siempre que queramos recopilar información para luego insertar citas y crear bibliografía deberemos utilizar gestores de referencias. En el mercado hay muchos, desde los gratuitos como Zotero o Mendeley, o de pago como EndNote, RefWorks, etc.
Personalmente utilizo Zotero, aunque en principio todos hacen lo mismo y ya depende de los gustos y necesidades de cada uno el elegir un gestor en concreto. Todos los gestores (que conozco) permiten crear cita y bibliografía de casi cualquier objeto, no sólo de un artículo científico o un libro, también de podcast, vídeos, imágenes, tesis, leyes… y si el gestor no puede crear la cita de forma automática, permite que seamos nosotros quienes la creemos a partir de un formulario donde incluimos los datos del elemento en cuestión. En Zotero, por ejemplo, tenemos estas opciones:
Cuando seleccionamos uno de esos elementos se abre un formulario donde nos indica los campos que hay que completar para que luego Zotero pueda crear la referencia bibliográfica en el estilo que marquemos. Fácil. ¿Pero qué pasa cuando queremos hacer la referencia de un elemento que no está en ese listado? Pongamos el ejemplo de un prospecto de un medicamento.
En este caso, Zotero no nos da la opción para crearlo de forma automática, así que tendríamos que hacerlo a mano o seleccionar un elemento diferente que luego nos haga la referencia. Primero os voy a contar cómo podríamos crear la referencia a mano.
Crear la referencia a mano:
Para ello tendremos que consultar las especificaciones de cada estilo de citación. Recuerda que una referencia bibliográfica lo que pretende es facilitar la localización de la fuente original. Veamos algunos ejemplos de citación de prospecto de medicamentos:
– ICMJE – Estilo Vancouver
EL NLM Style Guide for Authors, Editors, and Publishers no contiene información específica sobre cómo citar prospectos, por lo que se sugiere el siguiente formato basado en el estilo Vancouver (ejemplo en castellano e inglés):
Nombre del medicamento [prospecto]. Fecha de publicación: nombre del laboratorio; Año de publicación.
Drug name [package insert]. Place of publication: Manufacturer’s name; Year of publication.
– Estilo AMA para estudiantes de farmacia
Nombre del medicamento. Prospecto. Nombre del laboratorio. Año.
Nombre del laboratorio. (Año). Nombre del medicamento: título del prospecto. Lugar de publicación: Autor
Manufacturer’s name. (Year). Drug name: Title of package insert. Place of publication: Author.
En el estilo APA, el «publisher» es el laboratorio o compañía farmacéutica, que ya ha sido listada como autor, por lo que, en vez de volver a listar su nombre, se pone la palabra «Autor» (o Author en la cita en inglés) para indicar que el autor es el mismo que el «publisher». Incluye siempre el punto final. Para la cita en el texto se utilizará el nombre del laboratorio y la fecha. Por ejemplo:
(Merck Sharp & Dohme Corp., 2011)
Crear la referencia con Zotero:
Hemos visto que no existe el elemento Prospecto en Zotero, pero podemos utilizar la opción Página web:
Seleccionamos Página web (o web page si tenemos Zotero en inglés) y empezamos a completar los datos del formulario:
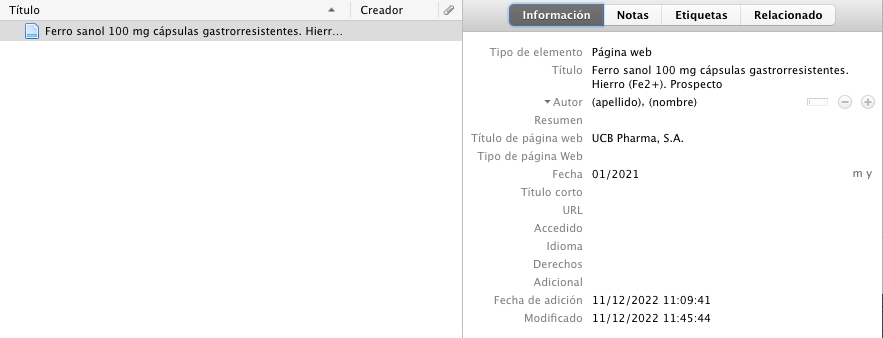
Título: incluimos el título que aparece en el prospecto y a continuación un punto y la palabra Prospecto. Por ejemplo: Ferro sanol 100 mg cápsulas gastrorresistentes. Prospecto.
Publisher/laboratorio y fecha de publicación. Aquí copiamos el nombre de la compañía que se responsabiliza del prospecto (suele ser el titular de la autorización de comercialización). Esto lo incluimos en el apartado Título de la página web (o Website title): UCB Pharma, S.A. La fecha se refiere a la fecha de la última revisión de ese prospecto: Enero 2021.
Accedido: si lo hemos consultado online, incluiremos también la fecha de consulta online: 13/12/2022
Si descargamos el prospecto en pdf podemos incluirlo junto a la referencia.
Si estamos haciendo la referencia de un prospecto en papel no incluiremos el campo URL ni el campo Accedido (ver las dos imágenes a continuación). Comprobad el formato de salida por si hubiera que modificar algo a mano para adecuarlo al estilo solicitado, ya que hemos seleccionado la opción Página web y puede que aparezcan elementos no necesarios.
Dónde localizar los prospectos o ficha técnica
La ficha técnica es la información sobre los medicamentos dirigida a los profesionales sanitarios. Los prospectos son los documentos en papel que encontramos en las cajas de los medicamentos con información para los usuarios (pacientes y familiares). En ambos casos la AEMPS los facilita en internet.
Es muy importante que nuestros pacientes puedan entender la información de estos prospectos. En el caso de que tengamos pacientes con dificultades de lectoescritura podemos dirigirles a la web de CIMA donde hay varios vídeos que explican en qué consiste un prospecto y cuáles son sus secciones, explicado además en lenguaje de signos para poder llegar a más público:
La semana pasada salió a la luz la herramienta ChatGPT creada por OpenAI. El acceso, de momento, es gratuito: sólo requiere registrarse y lo podéis hacer desde este enlace: chatGPT. Pero antes de empezar a jugar o cacharrear con la herramienta deja que te cuente algunas cosas que te pueden resultar de utilidad.
Te explico qué es: es un sistema conversacional basado en inteligencia artificial. Tú preguntas y el sistema responde. Pero que responda no significa que razone ni que haga cálculos ni que aprenda de tus respuestas. Es decir, es un modelo entrenado con un corpus extensísimo y en varios idiomas. Eso significa que «sabe» o «conoce» sobre todo lo que se le ha enseñado previamente. Según dice OpenAI, el corpus de entrenamiento tiene información hasta 2021. Pensemos en una persona que es capaz de aprenderse todo el texto de una enciclopedia. Cuando tú le preguntas algo y él tiene la información previamente guardada en su memoria, la saca y te la ofrece. Al mismo tiempo, si le preguntas algo que no sabe lo más seguro es que se invente la respuesta en base a su conocimiento adquirido previamente. En el caso de este sistema, un algoritmo decidirá qué palabra es la más probable que aparezca tras otra, y todo basado en los textos que ya tiene, así que la respuesta estará bien construida y será creíble. Pero no tiene por qué ser real. Si el interlocutor avisa de que esa respuesta es errónea, el sistema se disculpará y creará otra respuesta.
Ayer estuve probando ChatGPT y le pedí que me contara qué opinaba sobre la mala ciencia generada por las revistas depredadoras. Aquí podéis ver la primera respuesta:
Luego le pregunté qué eran las revistas depredadoras:
Le pedí una segunda respuesta a la misma pregunta:
Como veis, las respuestas son básicamente iguales. Todas las respuestas comienzan parafraseando la pregunta, que es el pie para empezar a contestar, y terminan con un resumen. Aquí es fácil distinguir que esta información la ha «leído» previamente, estaba entre ese corpus de entrenamiento, así que las respuestas siempre variarán sobre lo mismo.
Pero ¿qué pasa si le hacemos una pregunta sobre algo que no ha leído? Atentos a la pregunta y a la respuesta que da:
La respuesta que da es errónea, ya que el resultado de multiplicar 1325 por 72 es 95400. Lo que sí ha entendido es que se encuentra ante una multiplicación y sabe teóricamente cómo se multiplica, aunque realmente no sabe hacerlo. Ni puede. Pero la respuesta es categórica, rotunda. Si una persona no sabe multiplicar y lee esta respuesta probablemente la dé por buena.
¿A qué quiero llegar con todo esto? A que este tipo de herramientas a día de hoy (principios de diciembre de 2022) nos puede servir para apoyarnos a la hora de desarrollar un texto, un índice para preparar un trabajo o preguntar por ideas de marketing, por ejemplo. Pero también, a día de hoy, todavía es fácil que nos devuelva textos con información falsa pero presentada de manera firme y que puede confundirnos. Ojo, a día de hoy. Esto va tan rápido que puede que en un mes haya cambiado todo.
Nuestro papel como especialistas en información, da igual el campo de estudio, es poder ofrecer información fiable y relevante en todo momento. Parte de nuestro trabajo es ayudar a confirmar si la información que leemos o nos llega es real o inventada. Y aquí, por ahora, se nos abre un abanico importante donde podemos ofrecer las fuentes fidedignas. Porque sí, también le pregunté a ChatGPT si me podía dar las fuentes de la información que me ofrecía:
Así que nuestro papel como bibliotecarias se puede dividir en dos: por un lado, conocer cómo funcionan estas herramientas para poder explicar a nuestros usuarios en qué aspectos de su trabajo les puede ser útil usarlas, y sobre todo a distinguir el tipo de información que están recibiendo. Por otro lado, como gestoras de información deberíamos aprender a usar estas herramientas: creando preguntas precisas (generando prompts adecuados) recibiremos mejores respuestas. Pero también tenemos que aprender a filtrar esas respuestas y saber cuáles pueden tener un error (como en el caso de la operación matemática) o cuáles podrían ser correctas.
Recuerda: usa Google y ChatGPT, pero consulta también con tu bibliotecaria (humana) de cabecera. Estamos para ayudarte y para darte la respuesta correcta (y apoyada en bibliografía, por si lo quieres comprobar tú).
Cada base de datos tiene una sintaxis diferente. Conocer esta sintaxis nos va a facilitar la consulta a la base de datos y nos va a permitir recuperar registros más pertinentes.
Por ejemplo, si consultamos MedLine a través de PubMed podremos utilizar etiquetas de campo para decirle dónde queremos que nos busque los términos. Esto también se da en la búsqueda de MedLine a través de OVID o de Embase. Pero cada base de datos se consulta de una forma diferente. Además, no todas las bases de datos ofrecen las mismas opciones de búsqueda.
En el caso de Embase tenemos la opción de utilizar operadores de proximidad (NEAR y NEXT) para indicarle a la base de datos que queremos que dos términos estén juntos o próximos entre sí:
NEAR/n busca términos entre el número especificado de palabras (n) entre cada uno de los términos y en cualquier dirección: therapy NEAR/5 sleep busca la palabra therapy separada un máximo de 5 palabras de la palabra sleep (en cualquier orden).
NEXT/n igual que NEAR, pero aquí es obligatorio que las palabras se encuentren en el orden indicado: no devuelve lo mismo NEAR que NEXT
En OVID también tenemos un operador de proximidad: adj:
adj1: los dos términos juntos, en cualquier orden
adj2: los dos términos juntos, en cualquier orden, separados por un máximo de una palabra
adj3: los dos términos juntos, en cualquier orden, separados por un máximo de dos palabras
Hasta hoy PubMed era la única base de datos que no ofrecía operadores de proximidad, por lo que la única forma que teníamos era el uso de comillas para buscar una frase concreta: «sleep therapy» o bien buscar para que aparecieran los dos términos, independientemente del orden y del número de palabras que los separasen: sleep AND therapy. El problema de esto es la cantidad de ruido documental (registros no relevantes) que se recuperaban.
Pero esto ha cambiado: a partir de ahora PubMed permite la búsqueda de proximidad.
Esta búsqueda sólo se puede hacer en dos campos: en título y en resumen, y se especifica dentro de los operadores de campo [title] [ti] y [title/abstract] [tiab]. Su funcionamiento es similar al operador de proximidad de OVID, es decir, buscará los términos separados por el número de palabras especificadas, indistintamente del orden de las mismas.
Vamos a escribir [title:~0] cuando buscamos los dos términos seguidos, en cualquier orden:
«rationing healthcare»[title:~0] nos devolverá cosas así:
Si buscamos por «rationing healthcare»[title:~1] recuperaremos cosas así:
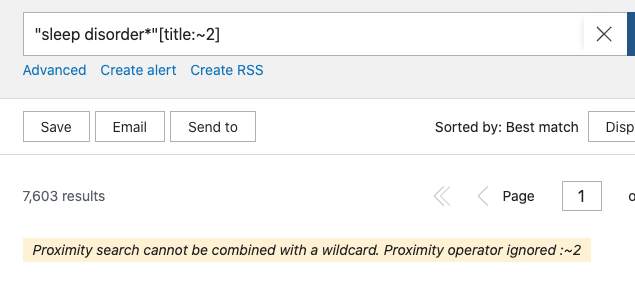
Para crear el operador de proximidad se utiliza el símbolo ~, que puedes crear pulsando las teclas Alt+126 en un teclado de PC o Alt+ñ en un teclado de Mac. La sintaxis es: «término término»[operadore de campo:~n] donde puedes cambiar operador de campo por [title] o la forma abreviada [ti] o por [title/abstract] o la forma abreviada [tiab] y donde la n se refiere al número de palabras que habrá entre un término y otro. Si escribimos un 0 PubMed entiende que han de ir juntas. No hay límite en el número de términos que se pueden incluir, aunque lo habitual es que se utilicen sólo dos.
Ten en cuenta que el uso de este operador de proximidad inhibe la búsqueda automática que hace PubMed, por lo que, por ejemplo, no buscará por el descriptor MeSH o las variantes de la palabra. Tampoco permite el uso del operador de truncamiento, así que la búsqueda «sleep disorder*»[title:~2] no funcionará e ignorará el operador de proximidad.
Como siempre, si tenéis cualquier duda sobre la sintaxis de búsqueda en cualquier base de datos, y ahora especialmente sobre este tema, podéis consultar con vuestra bibliotecaria de cabecera. O contactad con Alter Biblio si no contáis con biblioteca propia.
Es posible que muchos de vosotros me sigáis en twitter o en instagram y ya sepáis que el año pasado monté una empresa: AlterBiblio. Para los que no me seguís en redes sociales os lo cuento ahora: el año pasado monté una empresa. Se trata de AlterBiblio y se presenta como un nuevo concepto de biblioteca científica. Realmente tiene tres grandes pilares, que están interconectados entre sí y al mismo tiempo son/pueden ser independientes:
Biblioteca especializada en Ciencias de la Salud
Servicios de apoyo a los investigadores
Formación
La idea de montar empresa se debió a que vi que necesitaba crecer para poder ofrecer más y mejores servicios. Empezamos el año 2021 siendo 3 personas en AlterBiblio y contamos con 2 colaboradores fijos que nos permiten ofrecer más servicios. Ofrecemos servicios a instituciones relacionadas con las Ciencias de la Salud (hospitales, sociedades científicas, colegios profesionales, laboratorios…) pero también a investigadores individuales, profesionales sanitarios e incluso estudiantes.
AlterBiblio, tu otra biblioteca, busca ser un lugar de referencia donde buscar información y ayuda a investigadores. Ofrecemos servicios de pago, claro, pero también hemos querido conservar el espíritu de colaboración que hemos cultivado en Bibliovirtual desde que nació este blog. Para ello hemos creado un espacio en Discord. Esta plataforma, Discord, dispone de varios canales de texto, como si fueran canales de whatsapp o telegram, pero temáticos. También tiene canales de voz (donde se puede compartir audio, vídeo y compartir pantalla). En esta plataforma hemos creado la Comunidad de Intercambio y Aprendizaje de AlterBiblio, tu otra biblioteca. Esta comunidad dispone de varios canales temáticos relacionados con la investigación y la búsqueda y gestión de información científica. Hemos creado también dos canales de voz para charlar y para reuniones. La idea es seguir con aquella filosofía de SocialBiblio: todos tenemos algo que aprender y algo que enseñar; todos podemos ser alumno y profesor. Cualquier persona que se registre y se presente en esta Comunidad obtendrá permisos para consultar todos los canales. En cada uno de ellos podrá leer y aportar información. Si tienes alguna duda, por ejemplo sobre el uso de Zotero, puedes ir al canal de gestores de referencias y lanzar tu pregunta allí. Todos los miembros de la comunidad podrán leer tu duda y quien tenga la respuesta podrá escribirla, de manera que todo el mundo se beneficie del conocimiento compartido.
Os dejo el enlace a la Comunidad, por si queréis formar parte de ella. Os adelanto que para sacarle el mayor partido lo ideal es tener la aplicación de Discord instalada en el móvil y no tener reparo en compartir, preguntar y responder u opinar. Esta comunidad sólo es útil si se usa. También os comparto el enlace al apartado Blog de la web de AlterBiblio, que es donde iré posteando a partir de ahora.
El nuevo diseño de PubMed ya está aquí y también sus novedades en cuanto a su algoritmo de búsqueda. Ya en noviembre del año pasado hice un repaso de los primeros cambios que se anunciaron.
Aquí os dejo un recordatorio a modo de repaso rápido sobre la búsqueda que hace PubMed: cuando introducimos un término o frase en la caja de búsqueda de PubMed, éste aplica el Automatic Term Mapping (ATM), que consiste en una traducción del término según unas tablas predefinidas. Hace la comparación del término en cada una de las tablas y para el ATM en cuanto localiza una coincidencia. La primera tabla es Subject Translation Table (como novedad: comprueba nuestro término según grafía británica y americana, busca sus singulares y plurales; además de lo de siempre: añade sinónimos, busca su MeSH, subheadings, publication types…). La segunda tabla es Journals Translation Table (comprueba que el término se corresponde con el título o issn de una revista). Por último compara el término con la Authors Translation Table.
Me quiero detener en la parte de los autores. PubMed recoge un índice de autores desde 1946 con el formato apellido<espacio>inicial del nombre. A partir del año 2002 empieza a recoger también la forma desarrollada del nombre (apellido completo y nombre completo, no sólo la inicial). Por esta razón, cuando hacemos una búsqueda en PubMed y seleccionamos la opción de visualización Abstract, vemos que los nombres de los autores están desarrollados (siempre que los artículos sean posteriores a 2002).
La forma más efectiva de buscar un autor es por el formato antiguo de apellido<espacio>inicial del nombre, porque de esa forma nos aseguramos de recuperar también los artículos anteriores a 2002. Otra forma de buscar es pinchando sobre el autor que nos interesa y que vemos listado en una referencia. Esto provocará que PubMed nos muestre una página de resultados con todos los artículos que considera que corresponden a este autor seleccionado. ¿Y cómo sabe PubMed que un apellido e inicial se corresponde con un autor en concreto y no con otro con el que comparte esos datos?
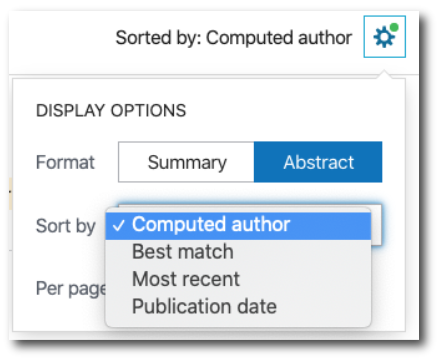
Computed Author
Esta funcionalidad la introdujo PubMed en 2012 y pretende ayudar a la desambiguación de los nombres comunes de los autores. Si PubMed encuentra un nombre de autor análogo para otras citas, ésas se mostrarán en primer lugar por orden de importancia, seguida de citas no similares. El proceso de desambiguación compara las citas con el mismo nombre de autor. La similitud de cada par de citas es medida por los metadatos de ambas citas (coautores, revistas, afiliación…) Las citas que comparten nombres de autores similares se dividen en diferentes grupos agrupando las citas que son muy similares entre sí. Las citas dentro de cada grupo se clasifican como pertenecientes al mismo autor. Esto empezó a implementarse en 2012, coincidiendo con la aparición de ORCID. Si el id de ORCID está incluido en los metadatos, será información que usará PubMed para desambiguar y poder ofrecer todos los artículos de un autor cuando se hace la búsqueda. ¿Qué conclusiones sacamos de esto? Primero, que todos los autores deberían tener un perfil en ORCID y firmar siempre igual. Segundo, que todos los editores deberían pedir el id de ORCID a los autores que publiquen en sus revistas. Tercero, que estos editores deberían incluir este dato dentro de los metadatos del archivo que se envía a PubMed para su indexación.
Durante estos primeros meses del año en el que PubMed hacía ajustes en su nueva interfaz, me topé de casualidad con la opción Computed Author dentro del apartado de ordenación de resultados. Supongo que estarían haciendo pruebas porque finalmente no dejaron la opción en el desplegable (entiendo que después de seleccionar esa opción habría que ordenar por orden alfabético ascendente o descendente), pero sí me dio tiempo a sacar un pantallazo:
Por último, aprovecho para publicitar el curso online que estamos preparando para el próximo 10 de junio de 2020. Mejora tus búsquedas bibliográficas con PubMed. Se trata de un curso online de 4 horas de duración que impartiremos desde AlterBiblio. Tenéis más información sobre contenido, precio e inscripción en este enlace: preinscripción al curso Mejora tus búsquedas bibliográficas con PubMed. Y si tenéis dudas o preguntas sobre este curso, podéis contactar en info@alterbiblio.com
Llevo tiempo con ganas de escribir esta entrada, pero no encontraba tiempo para sentarme tranquilamente a escribir.
En la entrada anterior os comenté que los bibliotecarios españoles de Ciencias de la Salud nos habíamos reunido y organizado para colaborar entre nosotros y ayudar así a nuestros usuarios. Queríamos optimizar el tiempo, ahorrar esfuerzos y mejorar los resultados de nuestro trabajo. Muchas bibliotecas de hospital cuentan con una sola persona al cargo. Algunos hospitales, por ejemplo La Princesa (Madrid) o el Universitario de Salamanca, han perdido a la bibliotecaria que tenían en plantilla y ahora no tienen especialistas que den un servicio de calidad a los trabajadores de estos hospitales. También hay hospitales que nunca han tenido biblioteca médica, como es el caso de muchos hospitales privados. Incluso algunas bibliotecarias tienen que dar servicio en más de una biblioteca de hospital. Resumiendo: si normalmente el volumen de trabajo da para no quedarte dormido en los laureles, suponíamos -con bastante acierto- que la situación provocada por el COVID-19 nos traería mucho más trabajo. Y que no sólo nuestros usuarios tendrían necesidad de localizar información fiable, también los usuarios de estos hospitales que no tienen biblioteca, o incluso población en general.
Como sabéis por las entradas que he ido publicando a lo largo de los años o por algunos de mis tuits, las bibliotecarias (o documentalistas) especializadas en Ciencias de la Salud nos dedicamos a muchas y variadas tareas, desde la búsqueda en diferentes bases de datos para localizar literatura científica, ayuda a los investigadores para entender y navegar por los mares de las acreditaciones, apoyo a los autores que quieren publicar (adecuación del manuscrito, revisión de las citas y bibliografía, localización de revistas donde publicar, explicar en qué consiste el Open Access y qué son las revistas depredadoras, los APC y los repositorios, etc.), formación especializada… En la mayoría de los casos ahorramos mucho tiempo a los usuarios. Tiempo que estos sanitarios dedican a atender a los pacientes, a investigar o a publicar. Y ese tiempo que el profesional sanitario no dedica a buscar información, es dinero que le está ahorrando a su empleador, ya que lo invierte en lo que realmente sabe hacer y no en algo que puede hacer otro profesional, en este caso un bibliotecario o documentalista. Me gusta explicar esto porque a veces hay gente que me dice que no somos necesarios, que los profesionales sanitarios pueden hacer ellos mismos las búsquedas, por ejemplo. Sí. Tienen toda la razón. Y también pueden limpiar el quirófano antes de cada operación. Y atender las llamadas de los pacientes y llevar la agenda de citas. No es que no sepan, es que hay otros profesionales mejor formados para hacer esas otras tareas. Y entre todos, cada uno haciendo su trabajo, mejoramos los resultados en conjunto.
Durante el estado de emergencia generado por el COVID-19 los bibliotecarios que estamos trabajando en equipo estamos dando servicio a nuestros usuarios compartiendo el conocimiento que tenemos entre nosotros y evitando reinventar la rueda si algo ya lo había hecho otro compañero. Pero hemos ayudado también a los usuarios huérfanos de bibliotecas que no tenían a un profesional de la información a quien acudir. Hemos querido ayudar, apoyar y ahorrar tiempo a los profesionales que estaban atendiéndonos a nosotros, los pacientes.
Genially creado por Concha Campos
Os decía al principio que creamos un grupo de Whatsapp que sirviera de medio de comunicación rápido entre nosotros. También tenemos un espacio en Google Drive donde hemos organizado en carpetas por temas y/o especialidades toda la información que vamos localizando. Algunos archivos pueden ir en varias carpetas, así que se duplican. Al principio compartimos estas carpetas con los profesionales, pero nos dimos cuenta de que algunos archivos desaparecían y otros se duplicaban en la misma carpeta, así que decidimos cerrar ese acceso y ofrecer la información de manera abierta a través de una web. Creamos un site de Google donde se pueden consultar todos los documentos. En este momento nos encontramos en fase de unificar títulos y crear las bibliografías de cada apartado para facilitar su consulta y que quienes vayan a utilizar los documentos puedan citarlos de forma apropiada. Tenemos también una cuenta en Gmail para recibir las dudas y peticiones de información. Y el hashtag que desde el primer día usamos en twitter: #AyudaBiblioteca y #JuntosParaAyudarte
La coordinación del grupo es bastante horizontal. No hay nadie en especial que lidere y todos participamos en la medida en que nuestro trabajo diario, obligaciones familiares y estado anímico nos lo permiten. Unos días unos están más que otros y otros días es al revés. Las dudas sobre organización del material, cómo contestar una pregunta llegada al grupo o dónde localizar información se hace desde el Whatsapp. Tenemos respeto, coordinación, camaradería, ayuda y buen humor. Ha sido un movimiento de nacimiento espontáneo y por ahora no nos hemos planteado qué pasará cuando termine esta pandemia. Pero nos está sirviendo para ver nuevas formas de trabajo, nuevas herramientas colaborativas, compañeros que hasta ahora no conocíamos. Hoy, con este post, quiero dar las gracias y mostrar mi admiración y respeto por mis colegas de profesión. Encontrarte gente así hace que me guste, aún más si cabe, mi trabajo.
Ya hace más de una semana que estamos en cuarentena. Esta misma semana, los bibliotecarios de Ciencias de la Salud de España (bibliotecarios de hospital, de universidades, de colegios oficiales, de sociedades científicas…) nos reunimos virtualmente para buscar formas de colaborar juntos y dar servicio a nuestros usuarios y a la población en general. En esta reunión virtual decidimos crear un grupo de whatsapp para comunicarnos más rápidamente y una carpeta en Drive donde subir documentación y trabajo interno.
La idea es optimizar el trabajo, sobre todo la localización de información fiable, porque supusimos -y acertamos- que íbamos a recibir peticiones muy similares por parte de nuestros usuarios. Entre todos, más de 70 participantes, hemos creado varios documentos de trabajo interno donde vamos recogiendo diferentes estrategias de búsqueda sobre el COVID-19 relacionado con otras patologías o temáticas.
En twitter hemos creado el hashtag #AyudaBiblioteca para poder seguir las consultas que nos hacen y poder dar respuesta unificada.
En definitiva: las bibliotecas de vuestros centros son importantes. Muchas veces pasamos desapercibidos, pero estamos dando apoyo constante, ahorrando tiempo de búsquedas para que nuestros sanitarios se puedan dedicar a lo realmente importante: cuidar de la población. Entre todos, personal de limpieza, restauración, logística, bibliotecas, etc. queremos y estamos para dar cobertura a nuestros sanitarios. Hacemos nuestro trabajo para que ellos se puedan centrar en el suyo.
Parafraseando Amanece que no es poco: «Todos somos contingentes, pero nuestra Salud Pública es necesaria».
Un fin de semana. 32 participantes de 10 comunidades autónomas diferentes, 2 charlas y un taller, 7 mentores, 8 equipos, 1 pregunta de investigación, 4 estrategias de búsqueda, 3 patrocinadores, varios colaboradores:
En este Searchathon que se celebró en La Nave el 16 y 17 de noviembre de 2019, nos juntamos un grupo variopinto de personas para mejorar en nuestros conocimientos de búsquedas bibliográficas en Ciencias de la Salud. Empecé a idear este evento en 2018 junto a mi amiga Karina Guzmán y no fue hasta marzo de este año que empecé a moverme para hacerlo realidad. Tras conseguir la localización y las fechas, y con el asesoramiento de HackathonLovers, empecé a buscar patrocinios. Había 3 opciones de patrocinio, desde una básica (Silver) a una Premium, incluyendo la posibilidad de patrocinar el evento completo. De todas las puertas a las que llamé (más de 20), 3 decidieron participar con el patrocinio Silver: Wolters Kluwer, Wiley y Elsevier. Al mismo tiempo se unieron varios colaboradores: desde María LaMuy que se encargó de la identidad visual: logo, camisetas e ilustraciones de la web; Ideágoras que ayudó con el diseño de la propuesta para patrocinadores y luego la grabación del vídeo que veis al inicio de este post; HackathonLovers con el apoyo logístico, asesoría y los voluntarios que nos acompañaron durante el evento; amigos que difundieron el proyecto entre sus redes (como Conectando Puntos con el «poscas» o HealthCare Creators con la entrevista); amigos personales y familia que me apoyaron, guiaron y estuvieron ahí durante todo el proceso. Y los ponentes/mentores que hicieron posible que la parte intelectual tuviera el nivel que tuvo.
Personalmente fue un reto y un proyecto en el que había puesto mucha ilusión, ganas, tiempo y dinero. Que saliera tan bien fue una gran recompensa. Que los involucrados (patrocinadores, ponentes, participantes, colaboradores y voluntarios) salieran contentos fue mi mayor logro.
¿Y cómo se desarrolló? Una de las primeras cosas que hice fue una web donde incluí la agenda prevista. Aunque el Searchathon comenzó el sábado 16, unas semanas antes ya teníamos montado un grupo en Telegram para hablar entre todos los participantes (desde temas de logística sobre alojamiento en Madrid, transporte, ubicación del evento hasta dudas sobre búsquedas, intercambio de enlaces, avisos informativos, etc.) y una semana antes organizamos dos webinars de la mano de dos de los patrocinadores: uno fue sobre búsquedas en Embase y el otro sobre búsquedas con la herramienta Ovid Search Builder. Además, OVID nos proporcionó unas claves para poder utilizar durante una semana esta herramienta y que los participantes pudieran ir practicando.
El sábado por la mañana lo dedicamos a charlas y talleres. José María Morán, Elena Pastor y Paula Traver serían los encargados de hablar sobre Metodología de la Investigación, Protocolo de búsquedas bibliográficas y el gestor de referencias bibliográficas Mendeley (este taller estuvo patrocinado por Elsevier). Previo al Searchathon yo había organizado los grupos intentando que fueran heterogéneos pero al mismo tiempo nivelados entre sí.
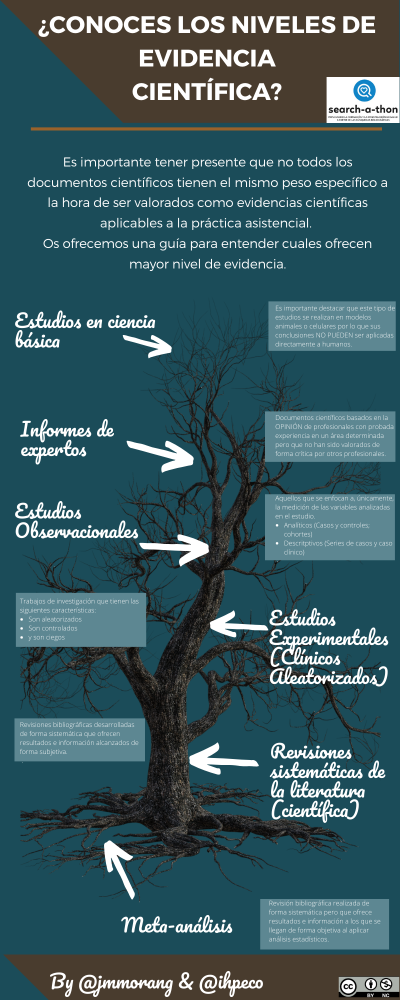
En este Searchathon se apuntaron varias bibliotecarias/documentalistas, casi todas especializadas en Ciencias de la Salud. También teníamos especialistas en medicina, en enfermería, en terapia ocupacional, en dietética y nutrición, en medical writing, en biología, en farmacia… también teníamos profesores de universidad, estudiantes e incluso un informático. Como veis, diferentes perfiles y diferentes niveles de conocimiento en búsquedas bibliográficas. Con los grupos ya formados y tras la comida les pasamos la pregunta de investigación que había preparado Concha Campos. Los participantes disponían de acceso a una carpeta compartida donde les habíamos dejado las presentaciones de José María Morán, Elena Pastor, Paula Traver, un documento creado por Marisa Maquedano con filtros metodológicos para diferentes bases de datos, varias infografías creadas por Iván H. Peco y las plantillas de resolución de las búsquedas bibliográficas.
Niveles de evidencia
Fases del proceso de investigación
Fase conceptual
Fase metodológica
Fase de verificación
El último día los participantes, por grupos, expusieron públicamente sus estrategias de búsqueda, contando las razones por las que habían elegido un término u otro y generando un debate interesante entre todos los asistentes. Los participantes, además, durante toda la competición tenían la posibilidad de consultar dudas a los mentores y cuando surgía alguna pregunta interesante la respuesta se hacía pública para todos los grupos, ya que la finalidad última del Searchathon era la formación. Eso sí, al final uno de los grupos fue el ganador de un premio a la búsqueda mejor enfocada y explicada.
En este Searchathon, que fue muy seguido en redes con el hashtag #SearchatonSalud, nos ha permitido aprender no sólo sobre investigación y búsquedas bibliográficas, también sobre trabajo en equipo, organización de eventos, atención a los detalles pequeños y que siempre hay gente interesante a la que conocer. A día de hoy seguimos compartiendo información y enlaces en el grupo de Telegram de los participantes. Si te interesa formar parte de él tendrás que apuntarte a la próxima edición de #SearchatonSalud.
Foto de familia de los participantes, mentores y voluntarios con la camiseta oficial del Search-a-Thon.
Y si quieres que te ayude a montar un Searchathon en tu institución, escríbeme.
Hace unos meses que sabíamos que PubMed cambiaría de interfaz y modificaría un poco su funcionamiento interno. A través de algunos webinars con la NLM y de los cambios que nos mostraban a través de PubMed Labs ya sabíamos cómo iba ser el diseño.
Avisaron de que en septiembre abrirían el nuevo PubMed y que éste estaría conviviendo con el antiguo hasta diciembre, fecha en que la nueva interfaz sería la visible por defecto. Pues bien, los cambios ya están aquí y casi sin previo aviso.
Todas las bibliotecarias sabemos que si hay un cambio en PubMed, éste ocurre el día antes de una formación. En mi caso ha sido «durante» la formación. No he podido explicar mucho y he tenido que esperar a llegar a casa para poder trastear un poco los cambios. Aquí va la primera impresión, pero tened en cuenta que no será hasta enero que los cambios se hagan realidad, y será en primavera cuando los cambios sean definitivos.
Old Pubmed vs New Pubmed
Como veis, en la nueva interfaz tenemos un cuadro de búsqueda que gana protagonismo. A simple vista es un estilo más moderno y más limpio que invita a buscar (en mi opinión al «estilo Google»). Voy a lanzar la misma búsqueda al mismo tiempo en ambos modelos y así podemos ir viendo las diferencias. Escribo en ambos campos de búsqueda diabetes mellitus type 2. Sin comillas y sin nada:
La primera diferencia es el número de resultados. En el antiguo PubMed (a partir de ahora Antiguo) tenemos 142751 registros frente a 142781 del nuevo PubMed (a partir de ahora Nuevo). Aunque podríamos pensar que es por la ordenación (en el Antiguo la ordenación por defecto es Most Recent, mientras que en el nuevo la ordenación por defecto es Best Match), al cambiar la ordenación del Antiguo me recupera 142766, número que tampoco concuerda con el Nuevo. Modificar la ordenación en Nuevo no influye sobre el número de resultados, que sigue siendo 142781 independientemente de si mostramos por Best Match o Most Recent. Tened esto en cuenta de cara a actualizaciones de búsquedas bibliográficas, revisiones sistemáticas, etc.
Otra diferencia es el formato de salida. En ambos por defecto se muestran los registros en formato summary, pero en el Nuevo el formato Summary muestra las primeras líneas del resumen, mientras que el formato Summary del Antiguo era sólo el título del artículo, autores, la referencia y los identificadores y enlace a artículos similares. En el Nuevo tenemos también el título, los autores (pero sólo muestra uno ó dos. Si el artículo tiene más de tres autores muestra el primero seguido de et al.), revista abreviada, año de publicación, pmid, y luego ya el inicio del resumen. Finalmente, en vez del enlace a artículos similares tenemos un enlace para ver la cita en diferentes formatos, descargarlo en .ris o copiarlo en el portapapeles. También un botón para compartir en Twitter, Facebook o copiar la url permanente de la referencia.
Diferencias de visualización del formato Summary en el Antiguo y en el Nuevo.
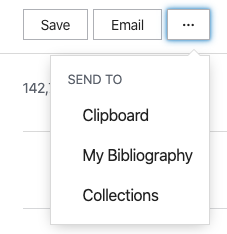
Más diferencias: El enlace Send to del Antiguo se convierte en dos botones visibles en Nuevo: Save, que permite guardar las referencias de esa página (o todas o una selección) en formato Summary, Ris, Abstract o CSV; otro botón Email que permite enviar por correo también una selección de registros de los resultados en formato Summary o Abstract. Para enviar los resultados al Clipboard o My Bibliography o a Collections tenemos que pinchar en el botón con 3 puntitos.
Diferentes visualizaciones de la opción Send to en el Antiguo y en el Nuevo.
Otra diferencia es el número de resultados que se muestran por defecto en cada página. En el Antiguo se mostraban 20 por defecto, pudiendo variar este número en la opción Per Page, teniendo justo al lado la posibilidad de saltar de una página a otra. En el Nuevo, la opción por defecto es de 10 registros por página y sólo al llegar al final de la página tenemos la opción de pinchar en el botón de Show more para ver los siguientes 10 registros o saltar a una página concreta. Si, por ejemplo, saltamos a la página 8 llegaremos al registro 80 y si queremos ver los anteriores tendremos que navegar de 10 en 10 o volver a elegir el número de página para saltar directamente.
Toda la información del menú lateral derecho del Antiguo desaparece en el Nuevo. Sólo se mantiene el gráfico de Results by year, que en el Nuevo se muestra sólo en la primera página y en la parte superior izquierda de la pantalla, justo sobre los filtros. Un apartado que echo mucho de menos (puede que lo encuentre más adelante, ya que estoy escribiendo el post al mismo tiempo que compruebo los cambios) es el apartado de información de las búsquedas Search Details: cómo Pubmed traduce la estrategia de búsqueda que le hemos lanzado. En el Antiguo se encontraba en el menú lateral derecho. En el Antiguo se encontraba también un apartado con las imágenes que Pubmed había encontrado en PMC sobre el tema de búsqueda. El enlace a gestión de filtros personalizados del Antiguo pasa al Nuevo con el nombre de MyNCBI Filters en la parte superior del menú lateral izquierdo.
Menú lateral derecho de Antiguo y los dos menús laterales izquierdos de Nuevo y Antiguo.
Visualización de un registro concreto
Si quisiéramos ver un registro concreto en el Nuevo deberemos pinchar en el título del artículo. Aquí ya vemos la referencia completa del artículo en la revista, todos los autores y podemos expandir para ver su afiliación. También nos muestra el pmid y añade el DOI que en la vista anterior no estaba. Los artículos similares que se perdían en la página de resultados se recuperan aquí justo después del resumen. A la derecha tenemos un menú con los enlaces al texto completo del artículo en fuentes externas, la posibilidad -de nuevo- de ver la referencia en diferentes estilos de citación, nos ofrece una nueva posibilidad: guardar el artículo como favorito (realmente es una colección privada con ese nombre), la opción de compartir el registro en redes sociales y una opción interesante: navegar para ir directamente a las partes interesantes del registro: título y autores; resumen; artículos similares; citado por; tipo de publicación; descriptores Mesh; LinkOut y más recursos. Al final de la página podemos navegar al registro anterior y al siguiente sin necesidad de volver a la página general de resultados.
Búsqueda Avanzada
Llegamos a la parte interesante (además de la diferencia de resultados, que necesito saber qué ha cambiado en el algoritmo de búsqueda de Pubmed para que el número de resultados sea diferente con los mismos datos de partida)
Vista de búsqueda avanzada en Antiguo y en Nuevo.
A simple vista, el nuevo diseño es más moderno y parece que más limpio. El orden del historial se invierte, colocando las nuevas consultas al final de la línea, en contraposición al historial del Antiguo que iba colocando las nuevas consultas en la primera línea.
La Query Box, que en el Antiguo estaba en la parte superior, ahora se coloca justo debajo del constructor de búsquedas. Visualmente tiene más sentido. En principio la construcción de queries es igual que antes. En el desplegable se selecciona el campo donde queremos hacer la búsqueda y en el cuadro de texto se escribe el término que queremos buscar. Por ejemplo busco en título/resumen la palabra hypertension y pincho en Show Index para ver cuántos registros existen con esa palabra en esos campos. Oh, sorpresa, no coinciden. En el Antiguo veo que hay 376676 registros mientras que en el Nuevo hay 379812. El segundo término tampoco coincide, así que empiezo a pensar que se han ampliado los campos de búsqueda en el Nuevo Pubmed. Si os fijáis en la segunda imagen, una vez que he lanzado la primera query, en el Nuevo se pinta esa query en la Query box, y se limpia el primer cuadro de texto, mientras que en el Antiguo se sumaba una nueva línea de cuadro de texto al mismo tiempo que se pintaba la query en la Query box. Personalmente este nuevo diseño me gusta más.
El botón Search del Nuevo lanza directamente la estrategia para ver los resultados, pero también nos permite enviar la estrategia al historial con el desplegable que nos ofrece el botón. Veamos el historial de búsqueda en el Nuevo:
Si os fijáis, un poco más arriba os comentaba que ya no teníamos el apartado de Search Details en el menú lateral derecho. Ahora se encuentra integrado en el historial. Para ver la traducción que hace Pubmed de cada estrategia tendremos que desplegar el apartado Details. Ahí vemos cómo mi estrategia diabetes mellitus type 2 la ha traducido como «diabetes mellitus, type 2″[MeSH Terms] OR «type 2 diabetes mellitus»[All Fields] OR «diabetes mellitus type 2″[All Fields]. Es la misma traducción que hace en el Antiguo. Los tres puntitos que se ven justo debajo de Actions permiten añadir esta estrategia a la caja de búsquedas con AND, OR, NOT, permite eliminarla del historial o guardarla en MyNCBI.
Hagamos una búsqueda buscando por descriptor Mesh
Si os acordáis, en el Antiguo se podía acceder a Mesh desde la búsqueda avanzada pinchando en la parte superior: More resources -> Mesh Database. Esta opción ha desaparecido en la búsqueda avanzada del Nuevo. Se puede seleccionar el campo MeSH Terms del desplegable, pero yo quiero poder buscar en el Mesh y ver la información del descriptor. Para esto tengo que volver a la home de Pubmed y buscar el enlace a Mesh Database, situado más o menos en el mismo lugar que en el Antiguo (listado de enlaces en la parte derecha de la pantalla):
La búsqueda por Mesh no ha cambiado, así que hacemos la búsqueda de la forma habitual. Compruebo que recuerda desde dónde he llegado y al lanzar la búsqueda del descriptor en Pubmed me devuelve a la interfaz anterior (Antiguo o Nuevo dependiendo desde dónde hubiera llegado). El número de resultados es el mismo, claro que aquí no hay misterio: sólo me va a mostrar los registros que tienen el descriptor Mesh indicado, no puede variar el número porque no es una búsqueda subjetiva.
Vamos a crear una alerta
En ambos casos nos pide que nos registremos en MyNCBI para poder crear una alerta. Una vez que hayamos accedido, los campos son los mismos, aunque el diseño es diferente:
Haber accedido al perfil personal de MyNCBI nos permite ver también los filtros personalizados que tenemos activos. En el Antiguo se encontraban en la parte superior del menú lateral derecho. Ahora los tenemos en la parte superior del menú lateral izquierdo, sobre los filtros por defecto de Pubmed.
Como veis, es un gran cambio de diseño, pero por los resultados de la búsqueda usando texto libre hay diferencias de resultados. Algunos detalles de diseño me gustan en el Nuevo, pero echo de menos algunas características del Antiguo. Aún siguen haciendo cambios y puede que reviertan decisiones o que hagan más cambios. Si os fijáis, al final de cada ventana, en la parte derecha, hay un botón verde para enviar Feedback. Usadlo sin temor.